

Ce que vous devez savoir sur la modélisation de la fiabilité des circuits électriques complexes
Cet article explore comment commencer à modéliser la fiabilité en utilisant une théorie classique d’évaluation de la fiabilité pour les systèmes complexes.
Malgré la complexité et les défis techniques, l’intérêt de l’industrie croît pour identifier les pannes imminentes et évaluer la santé actuelle des circuits électriques complexes, notamment pour les alimentations. Ce focus est motivé par les centres de données et les secteurs des télécommunications, où les pannes d’alimentation posent des risques significatifs.
Par exemple, selon un rapport de 2021 de l’Institute Uptime, le coût moyen d’une panne imprévue dans un centre de données est d’environ 740 357 dollars, avec 40 % des entreprises déclarant des coûts d’arrêt de plus de 1 million de dollars par heure dans l’enquête sur la fiabilité des systèmes d’exploitation serveur de l’ITIC. Par conséquent, assurer des opérations fluides et atténuer les impacts financiers sont des besoins urgents.
Approches traditionnelles de la modélisation de la fiabilité
Déterminer la fiabilité et l’état de santé des systèmes électriques, en particulier des alimentations, est complexe. Cette complexité provient des nombreux composants dans des conceptions typiques et des conditions extrêmes que les unités d’alimentation haute performance doivent endurer. En raison de la nature diversifiée de ces systèmes et de leurs environnements opérationnels, il n’existe pas de solution universelle.
Les approches potentielles pour évaluer la fiabilité des circuits électriques peuvent être divisées en quatre catégories principales, comme indiqué dans le tableau 1 ci-dessous. Les solutions varient selon que la modélisation est déterministe ou statique et si l’exécution se fait in-situ (par exemple, sur un contrôleur d’alimentation) ou ex-situ (par exemple, une application cloud).
Tableau 1. Différentes approches pour évaluer la fiabilité des circuits électriques.
| Nature déterministe | Nature statistique |
|---|---|
| Ex-situ Exemples Analyse de conception : Des techniques comme l’Analyse des Modes de Défaillance et de leurs Effets (FMEA) et l’Analyse des Arbres de Pannes (FTA) prédisent les points de défaillance potentiels sur la base des schémas de conception et des conditions de fonctionnement sans tests physiques réels. Modèles de prévision de fiabilité : En utilisant des méthodes de calcul du MTBF, des manuels comme Telcordia SR-332, MIL-HDBK-217 ou des modèles propriétaires, des méthodes statistiques sont appliquées aux données historiques de défaillance et aux formules empiriques pour estimer les taux de Temps Moyen Entre Pannes (MTBF) ou de Pannes en Temps (FIT). | Exemples In-situ Auto-Test Intégré (BIST) : Ce sont des routines de diagnostic intégrées qui fonctionnent au sein du système pendant son fonctionnement pour détecter des défauts et prévoir des pannes, assurant ainsi un suivi de santé en temps réel. Détection d’anomalies : La détection d’anomalies utilise des méthodes statistiques et d’apprentissage machine pour surveiller les données en temps réel, identifiant les écarts qui peuvent signaler de potentielles défaillances. |
Pour gérer les complexités de la fiabilité, il est judicieux de se pencher davantage sur la modélisation statistique et les modèles de prévision de fiabilité.
La courbe de baignoire
Une approche classique largement acceptée, la courbe de baignoire, comme illustré dans la figure 1, est fondamentale ici. Elle illustre comment le taux de défaillance évolue dans le temps et est décrite à l’aide de la distribution de Weibull.

La première phase du cycle de vie est la phase de mortalité infantile, qui présente un taux de défaillance élevé et rapidement décroissant en raison des appareils défectueux initiaux. La deuxième phase, la phase de vie normale, connaît un taux de défaillance relativement constant alors que la plupart des appareils défectueux ont échoué, et les effets de vieillissement sont minimes. La troisième phase, la phase d’usure, montre une forte augmentation des taux de défaillance due au vieillissement et à l’usure. La période entre les phases de vie normale et d’usure est la durée de vie du produit, généralement conçue pour éviter les effets d’usure.
Comprendre ces phases est crucial pour une modélisation efficace de la fiabilité et l’identification des stratégies.
Introduction des métriques de taux de défaillance
Le taux de défaillance, noté (Panne en Temps, FIT), mesure une panne par milliard d’heures de fonctionnement, indiquant la probabilité de défaillance dans un délai donné. L’inverse du FIT, le Temps Moyen Entre Pannes (MTBF) ou le Temps Moyen Avant Panne (MTTF), indique le temps moyen entre les pannes pour les systèmes réparables (MTBF) ou non réparables (MTTF). Cette discussion utilise le terme MTBF (mais les concepts sous-jacents s’appliquent également au MTTF), qui s’applique aux pièces ou aux systèmes entiers comme les alimentations, bien que les méthodes varient. Vous pouvez calculer le MTBF à partir des tests de terrain en utilisant la formule :
$$MTBF=frac{text{Temps Total de Fonctionnement}}{text{Nombre de Pannes}}$$
Pour les systèmes complexes, considérez le MTBF de chaque partie et leurs interactions en utilisant des diagrammes de blocs de fiabilité ou une analyse d’arbre de pannes. Les manuels de fiabilité peuvent modéliser et calculer le MTBF pour des systèmes complexes, ce qui est crucial pour concevoir des produits durables et identifier les points de défaillance potentiels avant les tests. Cela aide à planifier la maintenance pour prolonger la durée de vie des produits. Explorons maintenant l’application de la théorie de calcul du MTBF dans la pratique.
Modélisation des Taux de Défaillance avec le MTBF
Les pannes pendant la phase de vie normale sont d’un intérêt majeur dans le domaine. Les méthodes de calcul du MTBF, telles que spécifiées dans les manuels de fiabilité comme Telcordia SR-332 ou MIL-HDBK-217F, fournissent une approche structurée pour prédire et quantifier la fiabilité des composants et des systèmes électroniques ex-situ pendant la phase de conception.
Le processus commence par la collecte de données, y compris les spécifications des composants, les environnements opérationnels, les conditions d’application et les données historiques de défaillance. L’étape suivante consiste à estimer les taux de défaillance des composants individuels ((lambda_{comp} )). Les manuels fournissent des méthodes pour dériver les taux de défaillance de base ((lambda_{base} )) à partir de données empiriques ou des rapports FIT des fabricants peuvent être consultés. Par exemple, le rapport FIT d’Infineon pour le produit IPB014N06N répertorie un taux FIT et des conditions de test.
Le taux de défaillance de base ((lambda_{base})) est ajusté en utilisant des facteurs supplémentaires ((pi)) qui peuvent inclure les conditions environnementales, comme (pi_T) pour la température, et des contraintes d’application, comme (pi_{S}) pour le stress électrique. Par exemple, dans le graphique ci-dessus avec la courbe de baignoire, deux taux de défaillance observés (bleu et orange) pour différentes contraintes d’application sont illustrés. D’autres facteurs, tels que la qualité ((pi_{Q})), peuvent également être inclus.
Les taux de défaillance ajustés des composants sont obtenus en multipliant le taux de défaillance de base par les facteurs respectifs :
$$lambda_{comp}=lambda_{base}pi_{T}pi_{S}pi_{Q}$$
Le facteur d’accélération pour la température ((pi_T)) est généralement défini comme :
$$pi_{T}=e^{frac{E_a}{k_B}(frac{1}{T_0}-frac{1}{T})}$$
où :
- Ea est l’énergie d’activation spécifique au composant
- T est la température du composant/système respectif
- T0 est une température de référence
- kB est la constante de Boltzmann.
De même, le stress électrique ((pi_S)) est donné par :
$$pi_S=Ae^{B(s-s_0)}$$
où :
- A et B désignent généralement les paramètres de forme spécifiques au composant tenant compte du comportement spécifique du dispositif
- s est un paramètre de stress électrique,
- s0 est un paramètre de stress de référence.
Le paramètre de stress électrique dépend du composant comme le rapport d’une valeur appliquée et d’une valeur nominale :
Pour les résistances : s = frac{text{Puissance Appliquée}}{text{Puissance Annoncée}}
Pour les condensateurs : s = frac{text{Tension Appliquée}}{text{Tension Annoncée}}.
Le taux de défaillance du système est généralement calculé une fois que les taux de défaillance des composants individuels sont déterminés. Pour les composants en série, le taux de défaillance du système est la somme de tous les taux de défaillance ajustés des composants :
$$lambda_{system}=Sigmalambda_{comp}$$
Ici, des facteurs supplémentaires, tels qu’un facteur environnemental impactant tous les composants uniformément, pourraient être considérés, comme montré dans la figure 2. Pour les configurations en parallèle, des calculs supplémentaires sont nécessaires. Enfin, le MTBF est calculé comme l’inverse du taux de défaillance total du système. La figure 2 illustre l’approche globale et inclut des valeurs d’exemple :
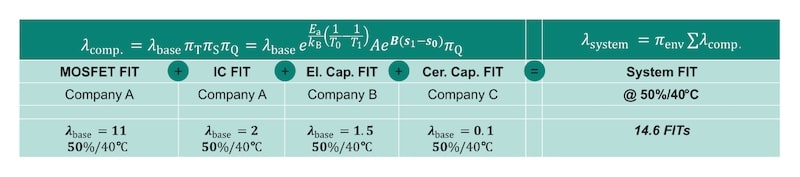
En suivant ces étapes, vous pouvez estimer systématiquement le MTBF pour les systèmes électroniques. Cependant, ces calculs sont limités par des hypothèses sur les profils de mission et les conditions de fonctionnement dans des scénarios ex-situ. Cette limitation peut être abordée en effectuant ces calculs in situ.
Conditions de fonctionnement et avantages de la modélisation in-situ
Le principal inconvénient des méthodes de fiabilité ex-situ est leur dépendance à des hypothèses antérieures comme les profils de mission ou les conditions environnementales, ce qui empêche d’obtenir des informations en temps réel sur la santé du système. La mise en œuvre d’un modèle de prévision de fiabilité in-situ, où les calculs et la surveillance se produisent au sein du système en tenant compte des conditions réelles de fonctionnement, offre plusieurs avantages par rapport aux approches traditionnelles ex-situ.
Pour remédier à ces inconvénients, Infineon a directement intégré la méthodologie des calculs de MTBF dans ses contrôleurs d’alimentation. En intégrant des prévisions de fiabilité ex-situ structurées et standardisées dans l’environnement in-situ, Infineon permet une surveillance en temps réel et un ajustement dynamique des taux de défaillance basés sur les conditions réelles.
Dans une application in-situ, le système surveille en continu les données en temps réel telles que la température, la tension et le courant. Ces données ajustent dynamiquement les calculs de taux de défaillance et les prévisions de MTBF en fonction des conditions réelles. Bon nombre de ces paramètres font déjà partie de la boucle de contrôle du contrôleur d’alimentation (par exemple, le contrôle PFC ou les boucles de contrôle LLC), comme le montre la figure 3, mais ils ne sont pas utilisés pour de tels calculs aujourd’hui.
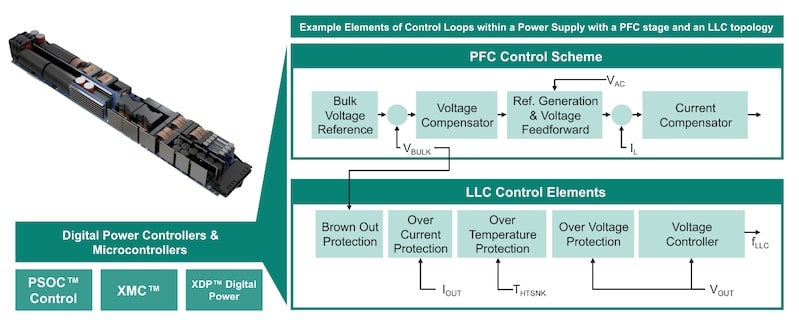
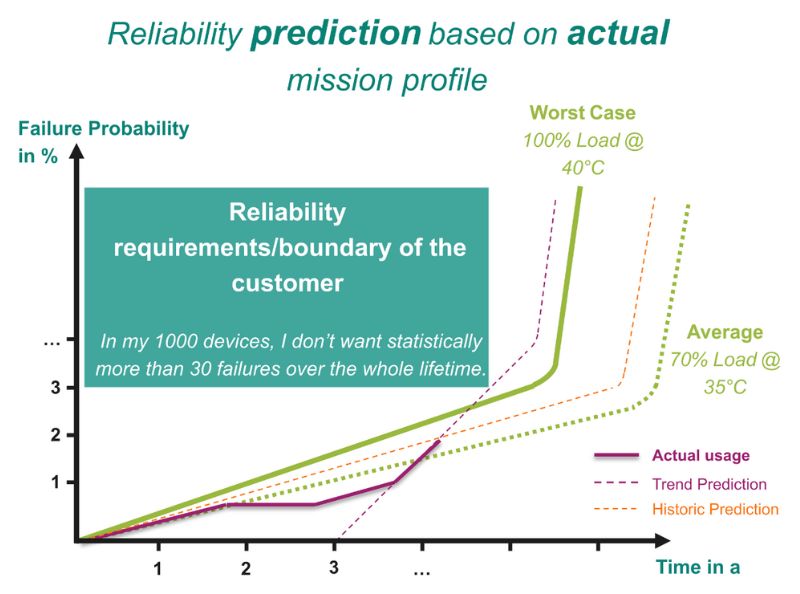
Les paramètres du modèle, y compris les taux de défaillance de base et les facteurs environnementaux, sont ajustés en fonction des données en temps réel, permettant un calcul continu des taux de défaillance ajustés et du MTBF. Cela permet de fournir des prévisions de fiabilité mises à jour à mesure que les conditions évoluent. Par conséquent, le système offre des alertes de maintenance proactive et des recommandations basées sur des métriques de fiabilité calculées, ce qui aide à comparer plusieurs systèmes. Bien que l’on puisse s’attendre, par exemple, que les alimentations dans un centre de données aient le même profil de mission, l’approche proposée permet de détecter les écarts par rapport à ces hypothèses, et les actions respectives peuvent être déclenchées.
L’exécution in-situ des méthodes de calcul du MTBF offre une plus grande précision grâce aux données en temps réel reflétant les conditions réelles, conduisant à des évaluations plus fiables et à de meilleures décisions. La surveillance continue et les calculs dynamiques identifient les problèmes potentiels avant que des pannes ne surviennent, réduisant ainsi les temps d’arrêt imprévus. Le système s’adapte aux environnements variés, garantissant des prévisions fiables même sous des stress inattendus.
De plus, comprendre les stress en temps réel optimise le fonctionnement pour prolonger la durée de vie des composants et améliorer la fiabilité globale du système. Cette approche de maintenance proactive et des prévisions de fiabilité précises peuvent réduire les réparations d’urgence et prolonger les intervalles de maintenance programmée, entraînant des économies de coûts. Les données de fiabilité en temps réel soutiennent une prise de décision améliorée pour la maintenance et les mises à jour. Le retour d’information continu dans le processus de conception aide les ingénieurs à affiner les futures conceptions sur la base des performances réelles sur le terrain.
Visitez Infineon pour plus d’informations sur la modélisation de la fiabilité des systèmes d’alimentation, y compris des détails sur le fonctionnement de l’implémentation in-situ, ou l’outil en ligne d’Infineon pour obtenir des premiers aperçus sur le potentiel de la solution.